Hypothesis and objectives
Hypothesis
Natural language is the main means of interaction in human societies. When these societies move to the digital world, the interaction between elements generates digital content, also mostly made up of natural language. Digital media and social networks have enhanced this interaction, creating an ecosystem of spaces where content is created and consumed in increasing quantity and speed. However, this ubiquitous environment of interaction has two opposing perspectives.
On the one hand, it is the repository of certain pervasive content that negatively affects the quality and freedom of information. Digital media have become a space where hoaxes, hate speech or abusive behaviour proliferate, among other content types that directly and negatively harm users of this space in particular and society in general. On the other hand, there is also a benefit generated by the sharing of valuable, quality and reliable information that generates a digital collective intelligence that can be used to the advantage of society as a whole.
Therefore, in this context, our main hypothesis is that human language technologies via the modelling the behaviour of digital content can contribute, on the one hand, to the detection, mitigation and prevention of harmful digital content, in pursuit of a sanitisation of social media on the Internet, and on the other hand, the characterisation of beneficial and trustworthy content, thereby making a valid and necessary contribution to the goal of ensuring a respectful, safe and trustworthy communication environment.
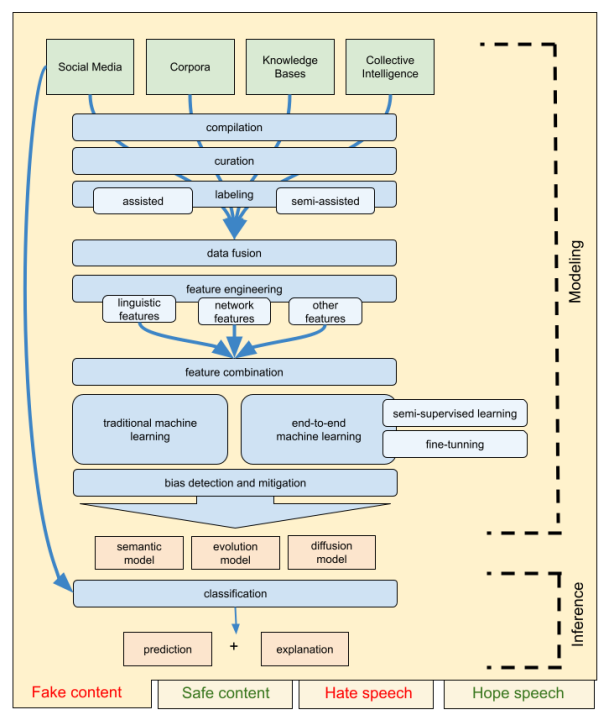
The previous figure shows a schematic diagram of the research concepts proposed in this project. This general diagram would be applied to each of the scenarios, both those referring to beneficial content (safe content and hope speech) and malicious content (fake content and hate speech).
Two main fronts are identified: modelling, where the learning and construction of the models from the data takes place; and inference, where these models are applied for automatic prediction of new content. We identify four preferred sources of information: publications in social networks, existing data collections, knowledge bases (structured data) and information obtained from platforms or collective intelligence mechanisms (such as through gamification or from structured and semi-structured content generation communities). All this heterogeneous content must be collected, filtered and labelled in a manual or semi-automated way, to be merged as homogeneous representations.
General objectives
- OBJ1. Automated resource generation leveraging collective intelligence.
- OBJ2. Studying and modelling the variety of digital contents based on semantic characteristics represented by digital entities.
- OBJ3. Analysis of the influence and impact of digital content in different scenarios.
- OBJ4. Generation of knowledge from the different digital models obtained.
- OBJ5. Application and evaluation of the acquired knowledge to real use cases in society.
Specific objectives of the CONSENSO Subproject (UJA)
- UJA1. Study of the adaptation and transfer of linguistic models in different contexts and languages.
- UJA2. Predictive models: behavioral modeling, text classification.
- UJA3. Interpretability and explainability: NER for interpretation of results.
- UJA4. Reliable NLP: fairness in NLP systems (evaluation of bias in language models).
- UJA5. Identification of application scenarios, in particular health and personal communications.
- UJA6. Generation of new resources by compiling data for subsequent annotation in the different project areas.
- UJA7. Hybridization and fusion of methods and techniques in NLP problem-solving.
Specific objectives of the TRIVIAL Subproject (UA)
- UA1. Prediction of mutation and virality of digital content: Behavioural analysis, extraction of behavioural patterns, emotional relationships, content traceability.
- UA2. Characterisation of content related to information disorder (disinformation, misinformation): hoaxes, digital impersionation, disinformative memes, leaks, hate speech, bias and polarity, etc.
- UA3. Construction and compilation of new tools and resources based on human language technologies to infer, create and utilize knowledge applied to digital content, focusing on the creation of semi-assisted annotators and their application to annotating resources.
- UA4. Extraction of high-level semantics to charaterise/define relationships between digital entities: contradiction, congruence, polarity, bias and emotional relationships.
- UA5. Representation and exploitation of high-level semantic knowledge between digital entities and their relationships.
- UA6. Application of Auto machine learning techniques in the identification of optimised NLP processes.
- UA7. Study of bias correction techniques in language models and anti-bias machine larning techniques applied to NLP.
- UA8. Characterisation of the different language scenarios studied in the project, specifically journalism and tourism.
- UA9. Construction and evaluation of prototypes and proof-of-concepts on the defined scenarios.