Hipótesis y objetivos
Hipótesis
El lenguaje natural es el principal medio de interacción en las sociedades humanas. Cuando estas sociedades se trasladan al mundo digital, las interacciones entre elementos generan contenidos digitales, también compuestos en su mayoría por idioma. Los medios digitales y las redes sociales han potenciado estas interacciones, creando un ecosistema de espacios donde el contenido se crea y consume en cantidades y velocidades crecientes. Sin embargo, este entorno ubicuo de interacción tiene dos perspectivas opuestas.
Por un lado, es el repositorio de cierto contenido generalizado que afecta negativamente a la calidad y la libertad de información. Los medios digitales se han convertido en un espacio donde proliferan bulos, discursos de odio o conductas abusivas, entre otro tipo de contenido que perjudica directa y negativamente a los usuarios de este espacio en particular y a la sociedad en general. Por otro lado, también existe un beneficio generado por el intercambio de información valiosa, de calidad y confiable que genera una inteligencia colectiva digital que puede ser utilizada en beneficio de la sociedad en su conjunto.
Por lo tanto, en este contexto, nuestra hipótesis principal es que las tecnologías del lenguaje humano a través del modelado del comportamiento de los contenidos digitales puede contribuir, por un lado, a la detección, mitigación y prevención de contenidos digitales nocivos, en busca de un saneamiento de las redes sociales en Internet, y por otra parte, la caracterización de contenidos beneficiosos y confiables, haciendo así una contribución válida y necesaria al objetivo de garantizar un entorno de comunicación respetuoso, seguro y de confianza.
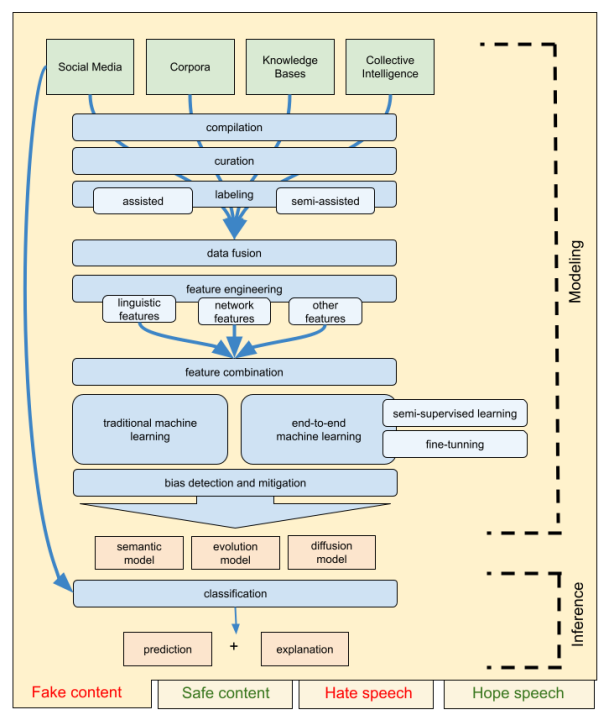
Esta figura muestra un diagrama esquemático de los conceptos de investigación propuestos en este proyecto. El diagrama se aplicaría a cada uno de los escenarios, tanto los referidos a contenidos beneficiosos (safe content y hope speech) y contenidos maliciosos (fake content y hate speech).
Dos frentes principales son identificado: el modelado, donde se lleva a cabo el aprendizaje y construcción de los modelos a partir de los datos; y la inferencia, donde estos modelos se aplican para la predicción automática de nuevos contenidos. Identificamos cuatro fuentes de información preferidas: publicaciones en redes sociales, recopilaciones de datos existentes, conocimientos bases (datos estructurados) e información obtenida de plataformas o mecanismos de inteligencia colectiva (como a través de la gamificación o de comunidades de generación de contenido estructurado y semiestructurado). Todo este contenido heterogéneo debe ser recogido, filtrado y etiquetado de forma manual o semiautomática para poder fusionarse como representaciones homogéneas.
Objetivos generales
- OBJ1. Generación automatizada de recursos aprovechando la inteligencia colectiva.
- OBJ2. Estudiar y modelar la variedad de contenidos digitales a partir de características semánticas representadas por entidades digitales.
- OBJ3. Análisis de la influencia e impacto de los contenidos digitales en diferentes escenarios.
- OBJ4. Generación de conocimiento a partir de los diferentes modelos digitales obtenidos.
- OBJ5. Aplicación y evaluación de los conocimientos adquiridos en casos reales de uso en la sociedad.
Objetivos específicos del Subproyecto CONSENSO (UJA)
- UJA1. Estudio de la adaptación y la transferencia de modelos lingüísticos en diferentes contextos y lenguas.
- UJA2. Modelos predictivos: modelado de comportamiento, clasificación de texto.
- UJA3. Interpretabilidad y explicabilidad: NER para la interpretación de resultados.
- UJA4. PLN confiable: equidad en los sistema de PLN (evaluación del sesgo en los modelos de lenguaje).
- UJA5. Identificación de escenarios de aplicación, en particular salud y comunicaciones personales.
- UJA6. Generación de nuevos recursos mediante la recopilación de datos para su posterior anotación en las diferentes áreas del proyecto.
- UJA7. Hibridación y fusión de métodos y técnicas en la resolución de problemas PLN.
Objetivos específicos del Subproyecto TRIVIAL (UA)
- UA1. Predicción de mutación y viralidad de contenidos digitales: Análisis de comportamiento, extracción de patrones de comportamiento, relaciones afectivas, trazabilidad de contenidos.
- UA2. Caracterización de contenidos relacionados con el trastorno de la información (desinformación, mala información): bulos, suplantación digital, memes desinformativos, filtraciones, discurso de odio, sesgo y popularidad, etc.
- UA3. Construcción y compilación de nuevas herramientas y recursos basadas en la tecnología del lenguaje humano para inferir, crear y utilizar el conocimiento aplicado a contenidos digitales, centrándose en la creación de anotadores semi-asistidos y su aplicación a la anotación de recursos.
- UA4. Extracción de la semántica de alto nivel para caracterizar y definir relaciones entre entidades digitales: contradicción, congruencia, polaridad, sesgo y relaciones afectivas.
- UA5. Representación y explotación del conocimiento semántico de alto nivel entre entidades digitales y sus relaciones.
- UA6. Aplicación de técnicas de auto machine learning en la identificación de procesos optimizados de PLN.
- UA7. Estudio de técnicas de corrección de sesgos en modelos de lenguaje y técnicas de machine learning anti-sesgo aplicadas al PLN.
- UA8. Caracterización de los diferentes escenarios lingüísticos estudiados en el proyecto, en concreto periodismo y turismo.
- UA9. Construcción y evaluación de prototipos y pruebas de concepto en los escenarios definidos.